

El diseño y desarrollo de software tiene en su caja de herramientas varias joyas que resultan vitales al momento de hacer sistemas de cierto tamaño.
Uno de ellos es el principio K.I.S.S. Tomado del contexto militar, este principio señala la importancia de mantener diseños sencillos, que puedan ser así fácilmente mantenidos. Y no sólo eso, un diseño simple, siempre que esté bien hecho, tiene la propiedad de permitir la modularización del sistema de una manera muy simple a su vez, sin necesidad de crecer el propio software a través de parches y refactorizaciones improvisadas.
K.I.S.S. es un acrónimo que, según la mayoría de las fuentes, significa "Keep It Simple, Stupid" (mantenlo simple, estúpido). Algunos dicen que el acrónimo insulta al receptor, otros sólo que hace referencia a que el diseño además de simple, debe ser muy muy básico (como para estúpidos).
En Podemos también buscamos seguir este principio en todos nuestros sistemas.
Este post es un ejemplo práctico de su aplicación. Por eso mismo seguro sale un post largote, y lleno de contexto no sólo técnico, sino también de negocio de microfinancieras. Advertidos están...
La Prevención del Lavado de Dinero
Resulta que el problema del lavado de dinero se ha tornado muy grave desde hace ya varios años. Ante esto, comisiones internacionales han pedido a sus miembros tomar medidas para detenerlo. En México, hay instituciones encargadas de hacer que instituciones, como las microfinancieras, tomen estas medidas.
Este año estamos implementando Matrices de Riesgo para medir el riesgo que una persona en particular que nos solicita un crédito puede representar en términos de lavado de dinero. Sin embargo no es una cuestión lineal, una escala del 1 al 10 para el riesgo y ya. Sino que se cruza también con el impacto económico que genera en nuestra institución el simple hecho de otorgarle o negarle un crédito a esa persona.
Las matrices de riesgo
De ese cruce (probabilidad de riesgo en materia de PLD vs impacto a la organziación) nace el concepto de las matrices de riesgo, con las cuales se pretende tener un mejor control e identificación de riesgos en la materia.
Un ejemplo de matriz de riesgo es el siguiente:
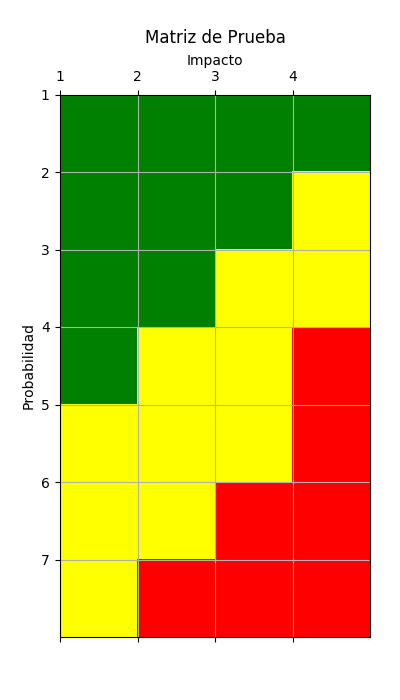
El eje X representa el impacto para la organización, el Y la probabilidad de riesgo de LD. Como se puede observar, la matriz está coloreada. El color verde indica la región en la que, si ahí se ubica la integrante, significa que no implica un grave riesgo de PLD ni un impacto grave para la organización. La zona amarilla es de alerta, que debe ser vigilada estrechamente. La zona roja indica que el riesgo y/o impacto es tan alto que el crédito no debería otorgarse.
El sistema que implemente esto debe:
- Valorar la probabilidad de riesgo (eje Y) de cierta cliente, con base en numerosas propiedades obtenidas en la solicitud del crédito.
- Valorar el impacto en la organización (eje X) de la misma, con parámetros similares, aunque no necesariamente los mismos.
- Ubicar a la posible cliente en un cuadrante de la matriz y registrar esto mismo
- Además debe poder consultarse, para tal cliente, qué parámetros se midieron en cada eje para llegar a esa ubicación en la matriz y en dónde se ubicó finalmente.
- Y con la posibilidad de consultar históricamente en qué cuadrantes de la matriz ha estado la cliente conforme han cambiado los parámetros.
- Además, la matriz que usemos no va a ser definitiva (¿qué sí lo es?), sino que tiene que poder cambiar en el tiempo, por lo que los históricos deben hacer referencia a la versión específica de la matriz que se usó para medir el riesgo tal en tal fecha.
El diseño original
El diseño del sistema para implementar estas matrices ocurrió después de un proceso que recuerdo bastante por lo anecdótico.
Originalmente pensé en un sistema con una base de datos relacional súper completa que registrara todos y cada uno de los cuadrantes de la matriz, por versión, y de esta forma al medir el riesgo de cierta cliente registrar exactamente donde se ubicó según este sistema.
Además debían existir una serie de tablas jerarquizadas para los ejes X e Y. La jerarquía se da por necesidad, ya que los parámetros se miden a través de categorías. Por ejemplo:
- La categoría entidad de domicilio (que es requerida para medir la probabilidad de riesgo)
- Tiene a su vez un grupo de variables: si vive en tales entidades el riesgo es uno, en otras es otro.
- Cada variable tiene un valor de probabilidad de riesgo determinado
- Tiene a su vez un grupo de variables: si vive en tales entidades el riesgo es uno, en otras es otro.
Esto último, no hay que olvidarlo, está determinado para cada versión de la matriz que tenga el sistema. Así que para una versión determinada este juego de jerarquías con sus categorías, variables y valores puede ser uno, en otra versión podrían existir las mismas categorías y variables pero cambiar los valores, o ser completamente distintos.
En fin, que en breve, el diseño más o menos tenía una estructura de E-R como la siguiente:
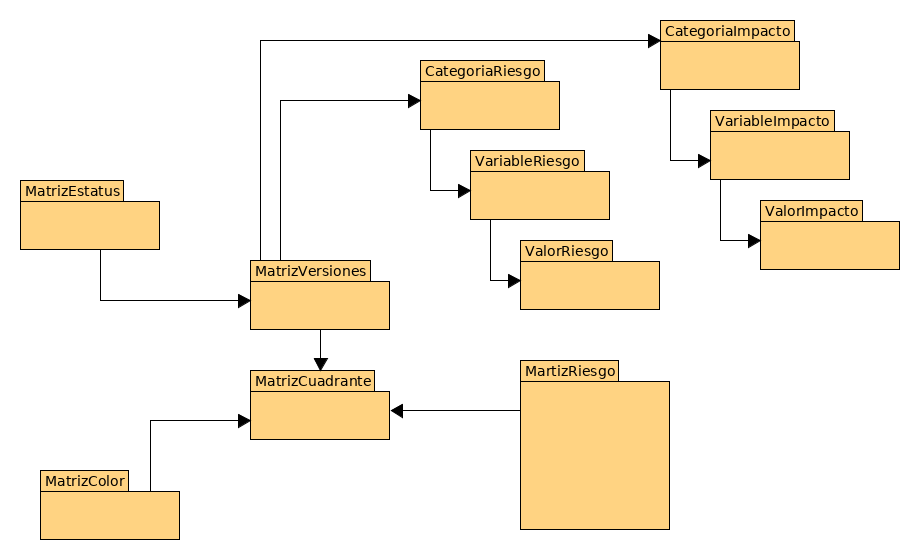
Básicamente, aunque en teoría todo funcionaría ahí, este diseño pretendía registrar cada parte del sistema en la base de datos. Cosa que es buena, hasta cierto punto.
El diseño, desafortunadamente, es extremadamente complicado. ¿Se imaginan implementando APIs y reglas de negocio usando un diseño así? Yo, la verdad, aunque veía el diseño correcto, ya imaginaba la tortura que iba a implicar para mi el implementarlo.
Sobre todo esa parte donde cada cuadrante de la matriz se guarda en un registro exclusivo de la tabla de cuadrantes, según la versión. ¿No hay forma de guardar toda la matriz por entero en cada registro? Y esa jerarquía de tablas para las categorías/variables/valores, ¿no podría simplificarse un poco?
Y de hecho sí...
La idea salió de mi colaborador en TI. Antes de que le mostrara este behemoth, ya había pensado en que las matrices podrían guardarse como texto plano, usando números para identificar los colores. Inicialmente estaba negado a esta idea, porque, erróneamente, concebía el sistema como 100% rastreable, completamente relacionado, perfectamente auto-contenido con sus deslumbrantes constraints que me ayudaran a no complicarme tanto la vida. Así que me quedé con mi idea original por esa noche.
KISS
Sin embargo al día siguiente, mientras me bañaba, iba pensando en esto (suelo hacer eso, muchas ideas me han salido justo en ese brillante momento ?) y ahí retomé la idea del texto plano, las matrices con números y TODO se simplificó...
Yo mismo me pude dar un zape por no haber recordado este principio el día anterior. El diseño no necesitaba ser tan complicado. Tantas tablas podían estar de más...
- ¿Y si en vez de guardar las matrices, un cuadrante por registro en la base de datos, usamos la idea del texto plano, PERO en vez de en una tabla de la base de datos, usamos archivos de texto plano? ¡Sí! Texto plano. El chiste no es que la base de datos guarde todo, el chiste es tener dónde guardar la información y poder consultarla y manipularla fácilmente. Un archivo de texto bien ubicado y nombrado elimina muchas tablas del diseño, y permite ver cómo queda la matriz final. Editar la matriz puede implicar simplemente generar una buena interfaz de usuario y generar desde cero un nuevo archivo de texto que sobreescriba (o versione) el anterior.
- ¿Y si extrapolamos esta idea a las jerarquías? ¿Qué tal si en vez de usar seis (¡SEIS!) tablas usamos sólo dos archivos de texto en determinado formato? Al final y al cabo son DOS los ejes de la matriz, tiene más sentido tener sólo DOS almacenes de información. YAML vino a mi mente. Formato perfecto, puede guardar información usando llaves y valores, como un diccionario, y eso fácil modela mis jerarquías. Y es un formato de texto plano legible hasta por humanos.
Me he topado con que mucha gente racionaliza mal al respecto de formatos de texto plano. Quizá piensen que un formato binario sea más práctico o más seguro o más pequeño. Ninguna de estas suposiciones suelen ser ciertas.
- En cuanto a práctico implica una implementación más complicada, y una documentación adecuada para no perderse al leerlo. Un archivo de texto plano, lo abres y lo usas, punto.
- En cuanto a seguridad, la información va a estar ahí, CUALQUIER ingeniero con buena formación sabe hacer una ingeniería inversa y descubrir lo que oculta dentro. La seguridad la puedes implementar en tu sistema de archivos, en tu servidor. Simple delegación de responsabilidades.
- Y en cuanto al tamaño, al menos en mi caso es tan pequeña, que es irrelevante 'comprimir' la información a nivel de bits.
Salí del baño a escribir todo esto (en casa me debieron ver raro apuntando todo en bata XD ). Y llegué a la oficina a dibujarlo y mostrarlo:
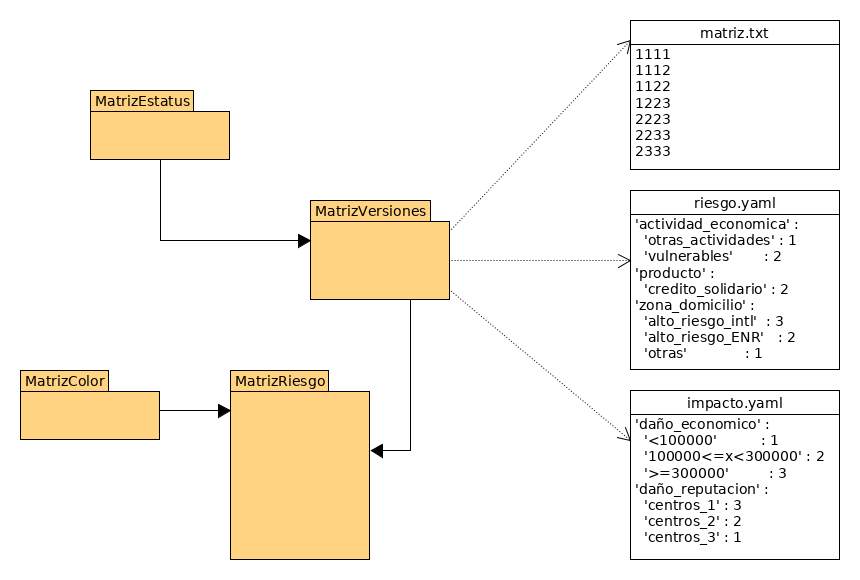
¡Qué diferencia! De ONCE tablas, a sólo CUATRO, mas tres archivos de texto plano que guardan información de manera clara y legible no sólo para el sistema, también para cualquiera que los abra para saber exactamente cómo es el modelo de matriz de riesgo para una versión específica de la misma.
Cuando queremos registrar el riesgo de una cliente simplemente hacemos referencia a la versión actualmente activa de la matriz y guardamos: esa versión, y una cadena de texto que permite saber en qué categorías, variables y valores está ubicada. Algo así:
para la probabilidad de riesgo, o una similar para el impacto.
Y con esa información podríamos generar imágenes como las siguientes, para saber visualmente en dónde se ubica una cliente:
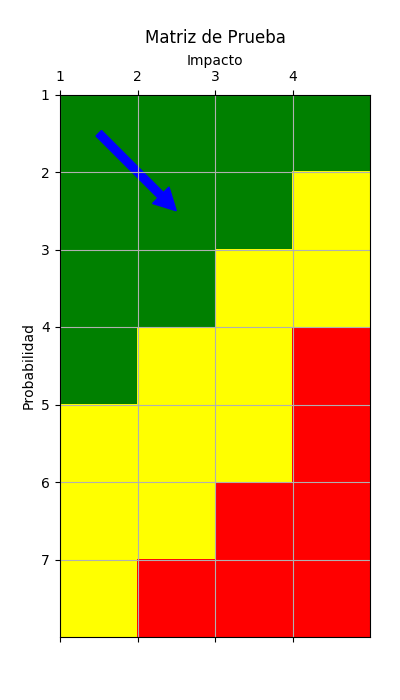
El sistema, tal como quedó, es muy práctico. Su implementación, sus APIs e interfaces de usuario, han sido sencillísimas de implementar. Escala muy bien. Además de los módulos para consultar el riesgo de determinada cliente sabiendo su histórico y a qué versión de la matriz corresponde algún registro, tenemos planeado un módulo de administración de versiones de matrices de riesgo, para que el usuario pueda dar de alta sus propias matrices y administrarlas a gusto.
En resumen, usar el principio KISS nos libró de tener que implementar un sistema que, por muy completo o correcto que pareciera, se iba a tornar muy pronto en un infierno de mantenimiento.