

Con este artículo comenzamos una pequeña serie, ¡la primera de este blog!, para hablar de DevOps en Podemos TI. Esta entrega sólo repasa los conceptos...
La segunda parte la pueden leer aquí.
La tercera y última parte la pueden leer aquí.
DevOps se ha vuelto todo un fenómeno en los ambientes de desarrollo de software. Casi una auténtica revolución.
Aunque, como veremos, muchos de sus principios y prácticas llevan existiendo en la industria (y en otras industrias!) por varias décadas, el haber integrado todo en esto que hoy conocemos como DevOps es lo que ha permitido a muchos equipos de TI lograr resultados en tiempos cada vez más exponenciales. Como se dijo, una auténtica revolución.

¿Qué es DevOps?
- En principio, ¿qué no es? DevOps no es una serie de prácticas aisladas que van a llevar a tu equipo de TI a ser más eficientes.
- DevOps tampoco es un conjunto de herramientas que debes implementar y con eso crees que ya garantizaste la calidad y la eficiencia al entregar resultados.
- DevOps tampoco es el nombre de un puesto de una persona, de esos nuevos que salen ahora, y que forma parte del equipo de TI para implantar mejoras.
En realidad, DevOps sí es todo lo anterior, JUNTO, y mucho más. La definición de la que me gusta partir es: DevOps es una cultura. A partir de la cultura se deriva todo: prácticas, herramientas, puestos... Y sólo en la medida en que esa cultura se viva, es que DevOps podrá ser exitoso.
El concepto de DevOps es relativamente reciente, del 2009, pero integra muchas prácticas y aprendizaje que han venido dándose, tanto en la industria del desarrollo de software como en otras industrias desde tiempo atrás. Éstas incluyen desde el movimiento ágil y el eXtreme Programming creado en Chrysler, hasta el Lean Manufacturing de Toyota (de los 70s-80s).
¿En qué consiste DevOps?
U n libro fundamental para entender DevOps es "The Phoenix Project". Al menos para mí lo fue. Escrito por Gene Kim et al, en realidad es una historia novelada (soy muy fan de leer novelas, así que por eso se me hizo más fácil). En la historia el protagonista, pobre hombre, se enfrenta al reto de lograr que su equipo comience a entregar resultados con un proyecto particular, y si no lo hacen, el equipo que va a hacer el trabajo a partir de entonces será subcontratado.
n libro fundamental para entender DevOps es "The Phoenix Project". Al menos para mí lo fue. Escrito por Gene Kim et al, en realidad es una historia novelada (soy muy fan de leer novelas, así que por eso se me hizo más fácil). En la historia el protagonista, pobre hombre, se enfrenta al reto de lograr que su equipo comience a entregar resultados con un proyecto particular, y si no lo hacen, el equipo que va a hacer el trabajo a partir de entonces será subcontratado.
Y digo pobre hombre, porque literalmente capítulo tras capítulo es sufrir con él, desgracia tras desgracia. Les pasa de todo. Cosas que a mi me han pasado, cosas que he escuchado que le pasan a otros, cosas que son parte del legendarium de TI, y cosas que ni se me hubiera ocurrido que podrían pasar... Espero esto no sirva de incentivo negativo, porque al final como en toda novela todo se resuelve.
A lo largo de la historia, un personaje se convierte en el gurú del principal y le va enseñando los principios que rigen al área de manufactura de la empresa y bajo los cuales esa área es siempre excelente en sus resultados. Y resulta, SPOILER, que gran parte de lo que le enseña viene de Lean Manufacturing...
Y es que, aunque a muchos les pueda hacer ruido, producir software, que no es lo mismo que fabricar partes de carro, al final de todas formas puede verse como una especie de línea de producción: tienes un requisito que debes cumplir y comienzas a fabricarlo. El producto debe irse integrando con distintas partes que se van fabricando, y debe ir pasando una serie de pruebas, y al final si todas pasan, el producto estará terminado.
Para ya no hacer el cuento largo, si hablamos de bits y bytes, tendremos un requerimiento al inicio, y luego de pensarlo, analizarlo y ver cómo empata con el resto del sistema, lo diseñas y comienzas a crearlo. Haces pruebas, te das cuenta que fallan y corriges, y una vez que pasan integras lo que llevas con otras partes, pueden ser partes del cambio solicitado, o puede ser simplemente el sistema con el que vas a integrar todo el cambio. Todo el tiempo se hacen pruebas, y si las pruebas pasan, puedes considerar el cambio listo, liberado y ya estará entregando valor al usuario.

Aquí es cuando el libro se pone un poco en tono hippie-zen... DevOps se puede entender a partir de las llamadas en el libro "Tres Vías", que si logras recorrer con tu equipo, te garantiza resultados extraordinarios... ¿Cuáles son esas tres vías?
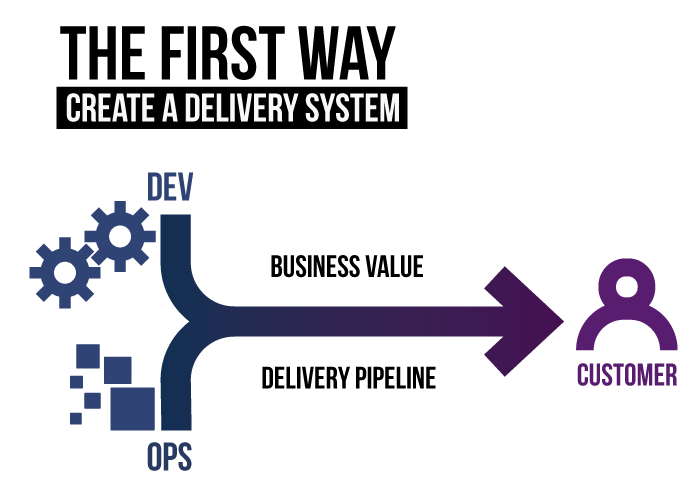 La vía del Flujo, (the principles of the Flow). Esta consiste en implementar prácticas, a través de herramientas y cambios en procesos, que te lleven a lograr mejorar esa parte donde se comienza con un requerimiento, y se termina con un producto terminado. Consiste en hacer más eficiente todo lo que tenga que ver con llegar al punto donde los cambios estén entregando valor al usuario final. Definitivamente, es la vía favorita de muchos, ya que es la que tiene que ver plenamente con nuestro rol de Desarrolladores del sistema. Es donde creamos y producimos y tecleamos código.
La vía del Flujo, (the principles of the Flow). Esta consiste en implementar prácticas, a través de herramientas y cambios en procesos, que te lleven a lograr mejorar esa parte donde se comienza con un requerimiento, y se termina con un producto terminado. Consiste en hacer más eficiente todo lo que tenga que ver con llegar al punto donde los cambios estén entregando valor al usuario final. Definitivamente, es la vía favorita de muchos, ya que es la que tiene que ver plenamente con nuestro rol de Desarrolladores del sistema. Es donde creamos y producimos y tecleamos código.
En ese sentido, prácticas como la Integración Continua y la Entrega Continua y el Despliegue Continuo son parte del juego de herramientas más importantes a implementar aquí.
Para lograr Integración Continua, son fundamentales las pruebas automatizadas. Si las pruebas de tu sistema las haces a mano, no vas a lograr entregar en tiempo nunca. Muchas de tus pruebas puedes, y es más debes, automatizarlas. Esto además de ser más rápido te da el beneficio añadido de que irás armando un juego de pruebas al que siempre puedes recurrir. Siempre ejecuta esta serie de pruebas y así no tendrás que hacerlas a mano posteriormente. Además, si unos meses más tarde haces otro cambio, las pruebas que ya tenías hechas te alertarán en el acto sobre cambios que podrían comprometer al sistema gracias a pruebas que ya tenías y te identifican ese tipo de compromisos.
Entrega y Despliegue Continuo son de alguna manera las dos caras de la misma moneda. En Integración Continua jugamos con lograr cambios que se integren al sistema de manera no dañina para el resto del mismo sistema. Pero acá, ahora jugamos con lograr meter a los distintos ambientes los cambios hechos en el sistema lo más eficientemente posible, usando herramientas que automaticen los despliegues por ejemplo.
Normalmente la diferencia entre Entrega Continua y Despliegue Continuo va de la mano en cuanto al grado de automatización que se tenga. Si para lanzar el despliegue se requiere alguna intervención manual, aunque implique sólo dar click en algún botonsito, se le llama Entrega Continua. Si por otro lado la automatización ya es tal, con todas las seguridades que eso implique tener antes, que nada más pasen las pruebas de la Integración Continua el cambio se auto-despliegue en el sistema productivo para ya darle valor al usuario de inmediato, se le llama Despliegue Continuo.
Otra de las posibles prácticas para lograr ser más eficientes en esta vía implica usar branches de corta vida para el desarrollo, lo cual motiva el release continuo. Un branch de desarrollo sólo va a existir mientras se está desarrollando un aspecto muy particular de algún cambio. Y la idea es estar liberando cambios, por muy pequeños que sean, constantemente. Aunque no sean la feature completa. El chiste solamente es que sean LIBERABLES, es decir, que no comprometan al resto del sistema, y que vayan aportando al sistema y al valor que entregan, aunque este valor se reduzca al simple hecho de que no truena nada. Además, usando técnicas como feature toggles, se pueden ir liberando muchos cambios aún incompletos pero que se mantengan apagados hasta que la feature sea liberada.
Tener branches de desarrollo de corta duración implica adoptar esquemas de versionado y control de repositorios particulares, muy adecuados para la eficiencia. Por ejemplo, Trunk Based Development. Nada de Gitflow, ni demás esquemas extra-complicados. En fin, que esta vía, la Vía del Flujo, consiste en hacer más eficiente la entrega de Valor al usuario. De ahí las prácticas como Integración, Entrega y Despliegue Continuos, los branches de corta duración, el release continuo, y el alto grado de automatización que se requiere.
En fin, que esta vía, la Vía del Flujo, consiste en hacer más eficiente la entrega de Valor al usuario. De ahí las prácticas como Integración, Entrega y Despliegue Continuos, los branches de corta duración, el release continuo, y el alto grado de automatización que se requiere.

La vía de la Retroalimentación, (the principles of the Feedback). Si la vía del Flujo consiste en hacer más eficiente la ida desde requerimiento hasta entrega de valor al usuario, la segunda vía consiste en extraer valor para un 'usuario' del sistema que siempre dejamos de lado: Nosotros Mismos. Y es que aunque por supuesto que hacemos sistemas para entregarle valor a un usuario final y a un cliente, olvidamos muchas veces que nosotros también somos una especie de usuario del sistema, pero un usuario muy especial, cuyo valor no está en el uso en sí que se le da al sistema, sino en cómo el sistema funcione y reaccione.
Tener esto en cuenta es importantísimo, ya que de la forma en que el sistema se sepa comunicar con nosotros en diversas situaciones dependerá el trabajo que tengamos que hacer después, ya sea para corregirlo o mejorarlo, o ya sea para repararlo en caso de fallas. Vaya, si el sistema se comunica pésimamente, hasta podríamos vernos en una situación extrema y quedarnos sin trabajo.
Pues bien, la segunda vía promueve las prácticas y herramientas que se necesiten para que nosotros, esta vez en un rol de Operadores del sistema, aprendamos cómo está respirando y funcionando el sistema, ya en vivo. Lo malo aquí es que muchos suelen identificar esto como mirar logs, y nada más. Y si por alguna cuestión organizacional no podemos mirar los logs directamente, necesitamos más formas de tener visibilidad. De ahí vienen todas esas herramientas de monitoreo y diagnóstico que, incluso si no pudiéramos acceder al sacrosanto servidor de producción, al menos deberían existir para que cualquier desarrollador sin permisos pueda ver como respira su sistema ya en vivo, y así diagnosticar problemas. Así que, la Segunda Vía trata justo de eso: de obtener Visibilidad.
Así que, la Segunda Vía trata justo de eso: de obtener Visibilidad.
 La vía del Continuo Aprendizaje y la Experimentación, (the principles of Continual Learning and Experimentation). Esta es, en lo personal, mi favorita. Porque sale más allá de lo técnico y pega en lo que debe ser DevOps en principio: una cultura.
La vía del Continuo Aprendizaje y la Experimentación, (the principles of Continual Learning and Experimentation). Esta es, en lo personal, mi favorita. Porque sale más allá de lo técnico y pega en lo que debe ser DevOps en principio: una cultura.
Para implementarla, más que herramientas y técnicas, lo primero que se requiere es una actitud: de siempre estar aprendiendo y mejorando. Por supuesto que implica mejoras en herramientas, técnicas y hasta procesos, pero si no se tiene la actitud, nunca se va a querer siquiera implementar.
¿Qué implica esta vía? En principio estar dispuestos a que el sistema falle. Porque el sistema VA a fallar, de formas que quizá nunca concebimos. ¿Qué pasaría si podemos CONTROLAR esta forma en que falla? Por lo menos en ciertas ocasiones previsibles, y sobre todo medibles. Pues que aprenderíamos y podríamos hacer un mejor sistema.
Las prácticas en esta vía pueden ser, en términos conservadores, bastante aventuradas, algunos dirían arriesgadas. Pero si todo lo tienes bien controlado, no hay por qué temer, y si hay mucho que ganar. Y el chiste de todo es APRENDER, para MEJORAR.
¿Sería posible tener un esquema de revisión de cada cambio que se sube a producción? Por un lado ganaríamos en que otro par de ojos ve el cambio y así puede detectar fallos, pero además quien lo vea aprende más del sistema y de cómo éste va creciendo.
¿Podría ejecutarse el juego de pruebas unitarias estando el sistema ya en producción? Lograríamos aprender si todo lo que se programó está funcionando tal cual fue pensado en nuestros entornos controlados de desarrollo (y evitaríamos el famoso 'es que en mi máquina si funciona').
¿Qué tal un proceso que en determinados días bien definidos tenga el único propósito de tirar alguno de los servidores de manera aleatoria usando un catálogo de vulnerabilidades comunes que se llegan a encontrar en aplicaciones y servidores? Y el objetivo sería no sólo volver a levantar el servicio, sino hacer las adecuaciones necesarias para que no vuelva a suceder, ya no por el proceso aleatorio sino por una situación de la vida real, que podría suceder en un horario poco práctico. Estaríamos haciendo nuestro sistema más resiliente. (Y, aunque no lo crean, es una práctica que SÍ hacen en la industria. Netflix lo implementa con su famoso Chaos Monkey). Y no sólo prácticas así tan... poco ortodoxas. Organizar sesiones de enseñanza y aprendizaje. Post-mortems efectivos luego de cada incidencia. Todo lo que tenga que ver con aprender más.
Y no sólo prácticas así tan... poco ortodoxas. Organizar sesiones de enseñanza y aprendizaje. Post-mortems efectivos luego de cada incidencia. Todo lo que tenga que ver con aprender más.
De esta forma, el propósito de la Tercera Vía es, lograr Aprendizaje, y con él Mejora Continua.
En futuras entregas, platicaremos de como se ve y mide DevOps a nivel mundial, y como lo tenemos implementado hoy en día en Podemos TI ;-)
Si quieres ver las siguientes partes de esta serie:
La segunda parte la pueden leer aquí.
La tercera y última parte aquí.